The Question That Started This
A user of AI Interview Analyzer ran a test. She set up a recruitment for a Personal Assistant role, tested the system with a candidate who was rude and boastful, and submitted the conversation for AI evaluation. The AI did not flag the attitude.
She wrote to us with three questions:
- How does the AI generate the evaluation criteria? Is it based on the details I provide?
- Why did the AI not note that his attitude would make him a bad fit for the position?
- Is this because of privacy protections? The candidate was rude and boastful. Would the AI not flag that?
This article answers all three. We also ran a controlled experiment to show exactly how much configuration affects the outcome.
How AI Generates Evaluation Criteria
When you create a recruitment in AI Interview Analyzer, the AI can generate evaluation criteria automatically. It reads everything you provide:
- Position name (e.g. "Personal Assistant to the CEO")
- Details / job description (the text field where you describe the role)
- Uploaded files (you can attach a PDF, Word document, or multiple files: job description, competency framework, culture document)
- Interview type(s) you select (Screening, Technical, Behavioral, Cultural Fit, or Final)
From these inputs, the AI produces a set of criteria, each with a name, a weight (1 to 5), and a category. For our test job description, the AI generated 12 criteria across four categories: Executive Support Experience, Calendar Management, Travel Coordination, Communication Skills, and others.
Here is the important part: the AI generates criteria from what you give it. If your job description focuses on tasks (calendar management, travel coordination, meeting support), the criteria will focus on tasks. If the job description does not mention interpersonal skills, the AI will not invent them.
Most job descriptions are task-focused. The expectations about attitude, humility, and cultural fit live in the hiring manager's head, not on the job posting. That is not a flaw in the AI. It just means you need to transfer that knowledge into the system.
The Four Levers That Change Everything
The AI-generated criteria are a starting point, not a final answer. You have four configuration options that directly affect evaluation outcomes.
1. Custom Criteria
All AI-generated criteria are fully editable. You can modify them, delete them, change their weights, or add entirely new ones. This is where the recruiter adds the knowledge that is not in the job description.
For our PA test case, the job description said nothing about humility or professional courtesy. But any hiring manager for a PA role knows these matter. Adding two criteria, "Professional Courtesy" and "Humility & Self-awareness," gave the AI explicit permission to evaluate interpersonal behaviour. It immediately scored both at 2/10.
2. Criteria Weights
Each criterion has a weight from 1 to 5. A criterion at weight 5 has five times the influence on the final score as a criterion at weight 1. Default weights are usually 3.
If interpersonal skills are critical for the role, set their weight to 4 or 5. If a technical skill is a nice-to-have, set it to 1 or 2. The weights tell the AI what matters most to you.
3. Interview Type
When setting up the interview, you select the type: Screening, Technical, Behavioral, Cultural Fit, or Final. You can select multiple.
A Behavioral interview weighs soft skills and communication. A Technical interview weighs hard skills and domain knowledge. For a Personal Assistant role, Behavioral is the right choice. Technical alone will miss the attitude problem.
That is exactly what happened in our test. The interview was set to Technical only. The AI weighted hard skills accordingly.
4. Culture Document
You can upload your company's culture document or describe your values in the recruiter notes field. Even a brief bullet list works: "We value humility, patience, and collaborative problem-solving."
Without a culture document, the AI evaluates against generic professional standards. With one, it evaluates against your specific organizational values. The difference is measurable: in our experiment, the criterion "Humility" scored 2/10 without a culture document and 1/10 with one. The AI could now match the candidate's dismissive behaviour against a company that explicitly values respect, patience, and a service mindset.
Understanding the Scoring Scale
This is something many users misunderstand, so it deserves its own section.
A score of 7 to 8 is a very good candidate. The AI almost never gives scores above 8. This is by design.
A 9 or 10 would mean the candidate gave essentially perfect answers with extensive, verifiable evidence for every claim, showed exceptional depth on every criterion, and left no gaps at all. Real interviews do not work that way. Even strong candidates have moments of vagueness, miss a follow-up point, or provide partial evidence for some claims. That is normal and expected.
The practical scoring scale:
- 1 to 3: Weak. Significant gaps or concerns.
- 4 to 5: Below average. Some relevant experience but notable weaknesses.
- 5 to 6: Average. Mixed signals. May be worth a second look depending on the role.
- 6 to 7: Above average. Solid candidate with some areas for improvement.
- 7 to 8: Strong candidate. Clear evidence of competence and fit.
- 8+: Exceptional. Rare. Do not wait for this score to make a hiring decision.
The hiring recommendations follow a similar logic:
- Hire: Strong evidence of fit across most criteria. Confidence that this candidate can do the job well.
- Maybe: Mixed or insufficient evidence. Worth a second interview or additional assessment.
- Do not hire: Weak performance across key criteria, or serious concerns that override the numerical score.
If you see a 7.2 and feel disappointed, recalibrate. That is a strong candidate.
We Ran the Experiment
We were curious: criteria configuration matters, but by how much? If we take the exact same interview transcript and simply change the configuration, how much do the results move?
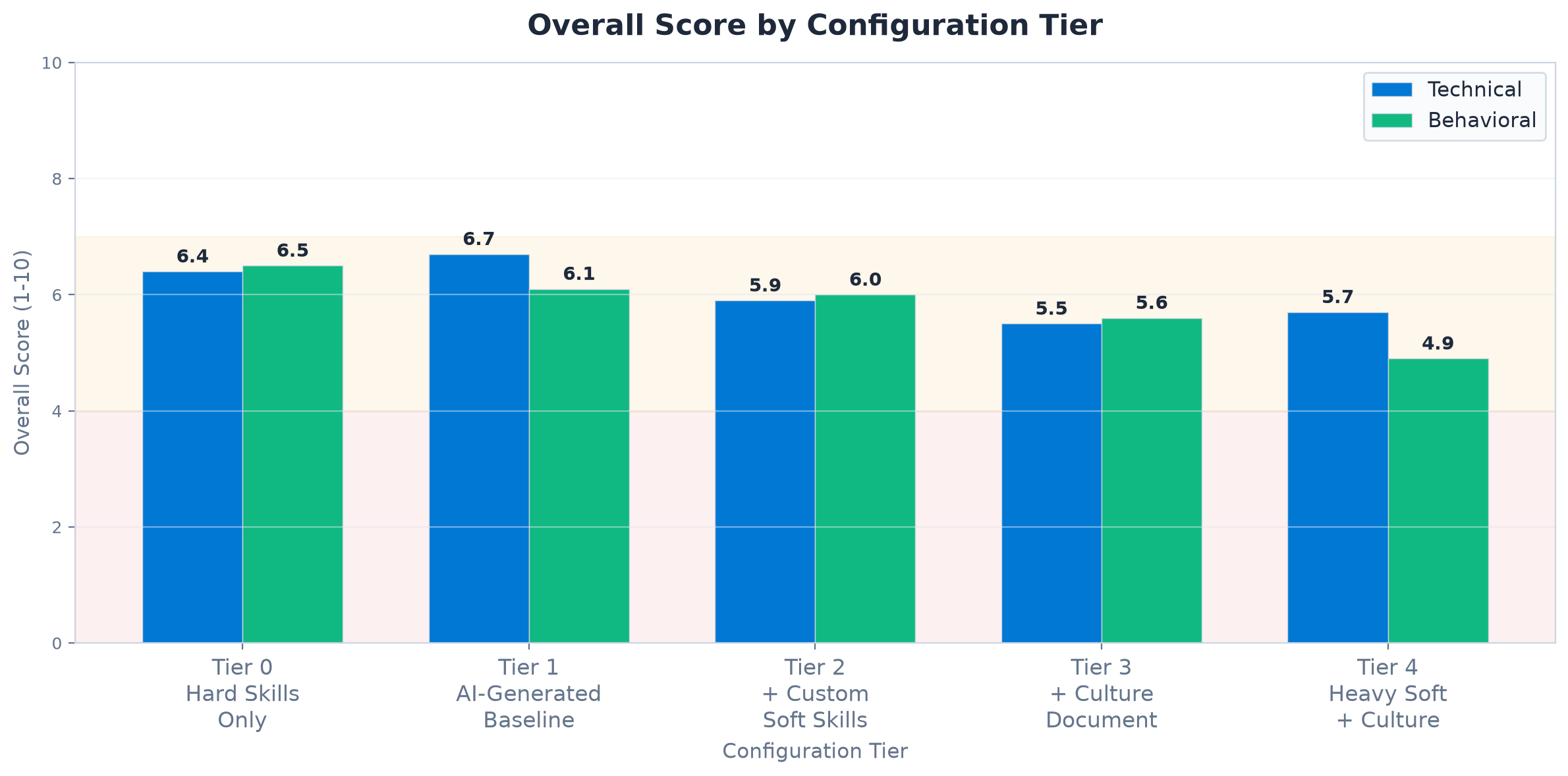
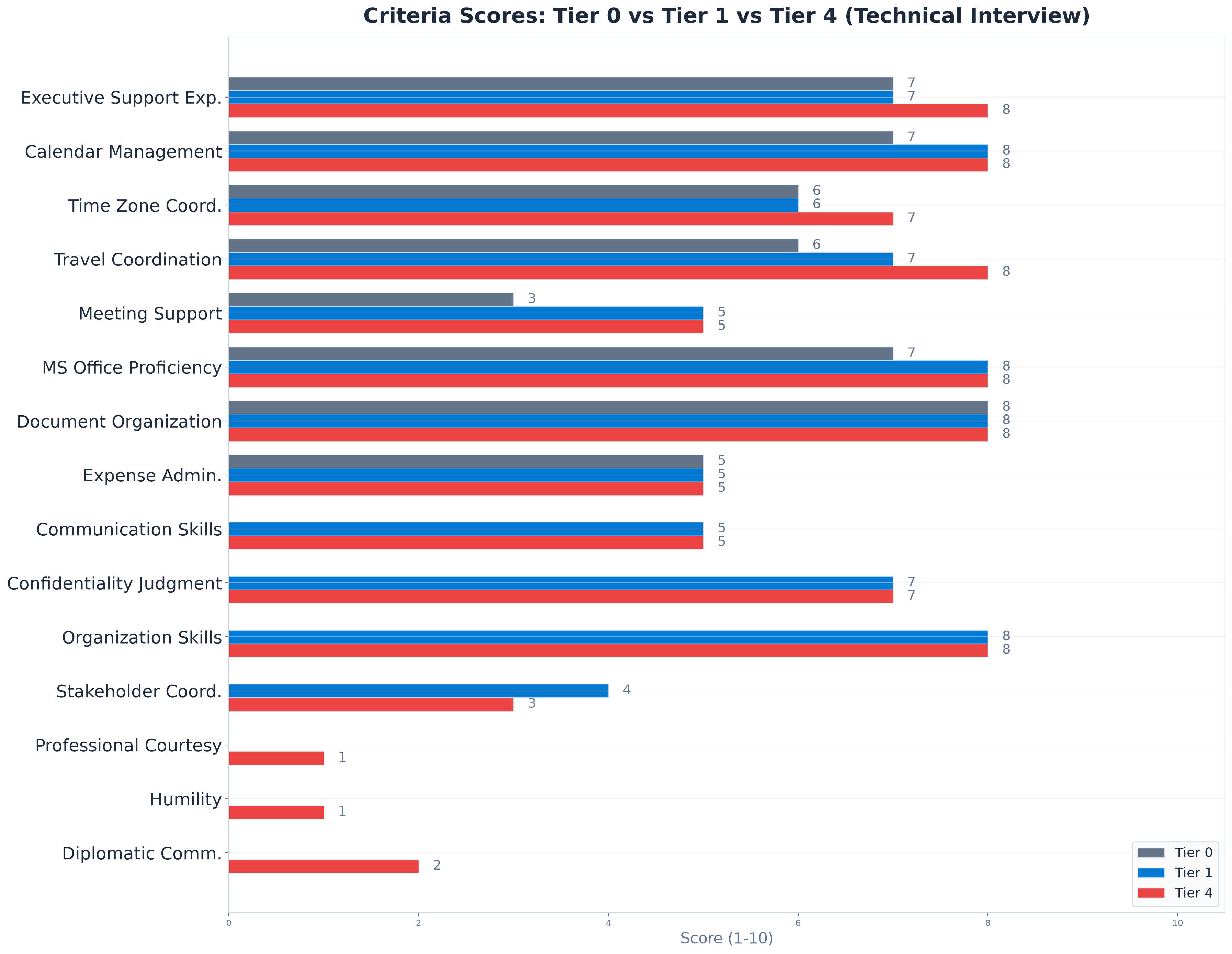
We ran 10 AI evaluations of the same transcript with five configuration levels, from minimal to comprehensive. Each tier was evaluated twice: once as a "Technical" interview and once as a "Behavioral" interview. All evaluations used GPT-5.4 on Azure OpenAI, running independently with no memory of previous runs.
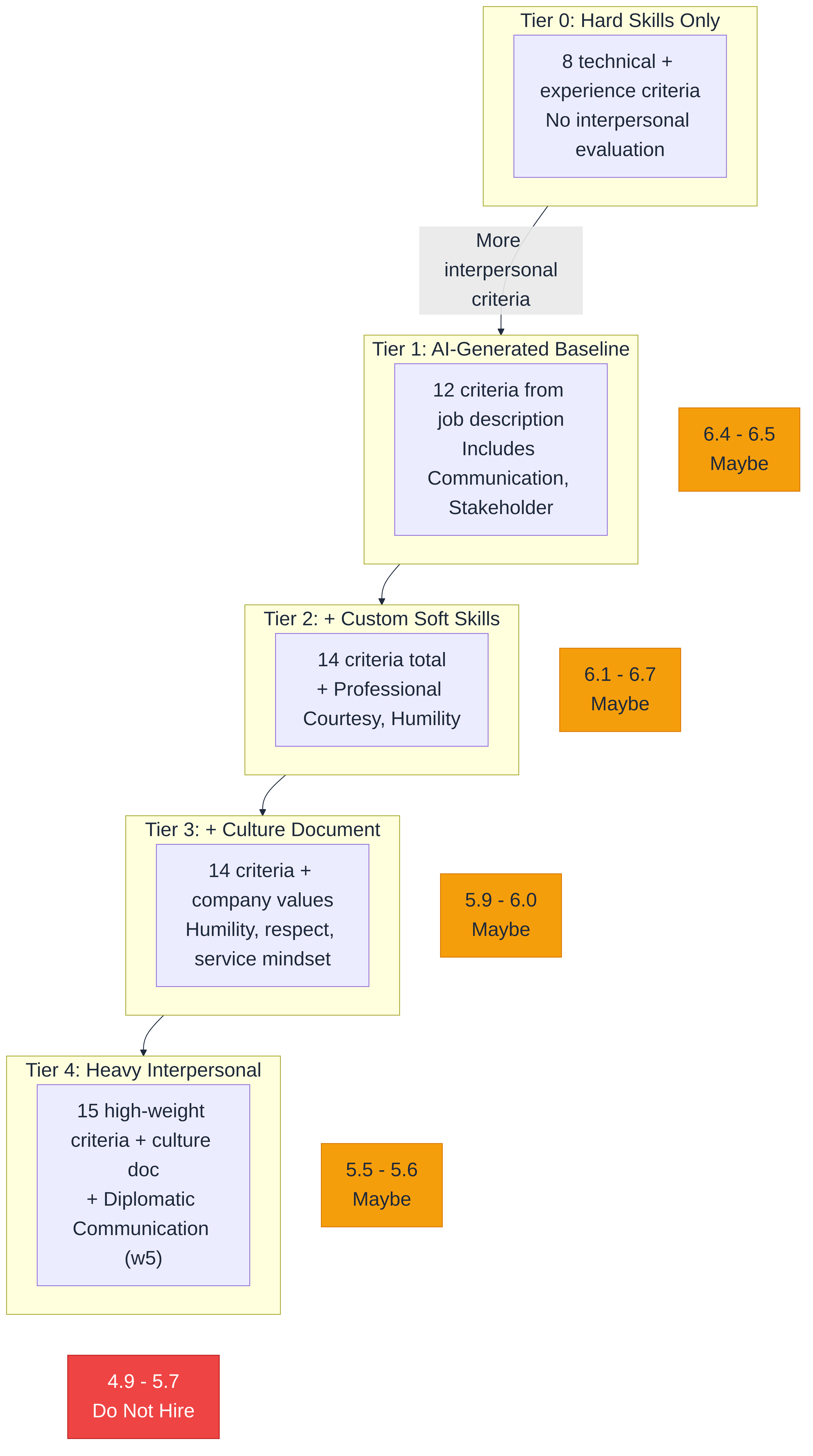
Tier 0: Hard skills only. Eight technical criteria. No interpersonal evaluation at all. Calendar Management, Travel Coordination, MS Office Proficiency, and similar.
Tier 1: AI-generated baseline. The full 12 criteria the AI produced from the job description. This is what you get out of the box when you paste the job description and accept the AI suggestions without changes.
Tier 2: + custom soft skills. Same 12 criteria plus two manual additions: Professional Courtesy (weight 4) and Humility & Self-awareness (weight 3). Fourteen criteria total.
Tier 3: + culture document. Same 14 criteria, but we also provided the company's culture document describing six values: humility, patience, active listening, collaborative spirit, discretion, and service mindset.
Tier 4: Heavy interpersonal + culture. Fifteen criteria with three high-weight interpersonal additions (all at weight 5), plus the culture document. Maximum configuration effort.
The Results
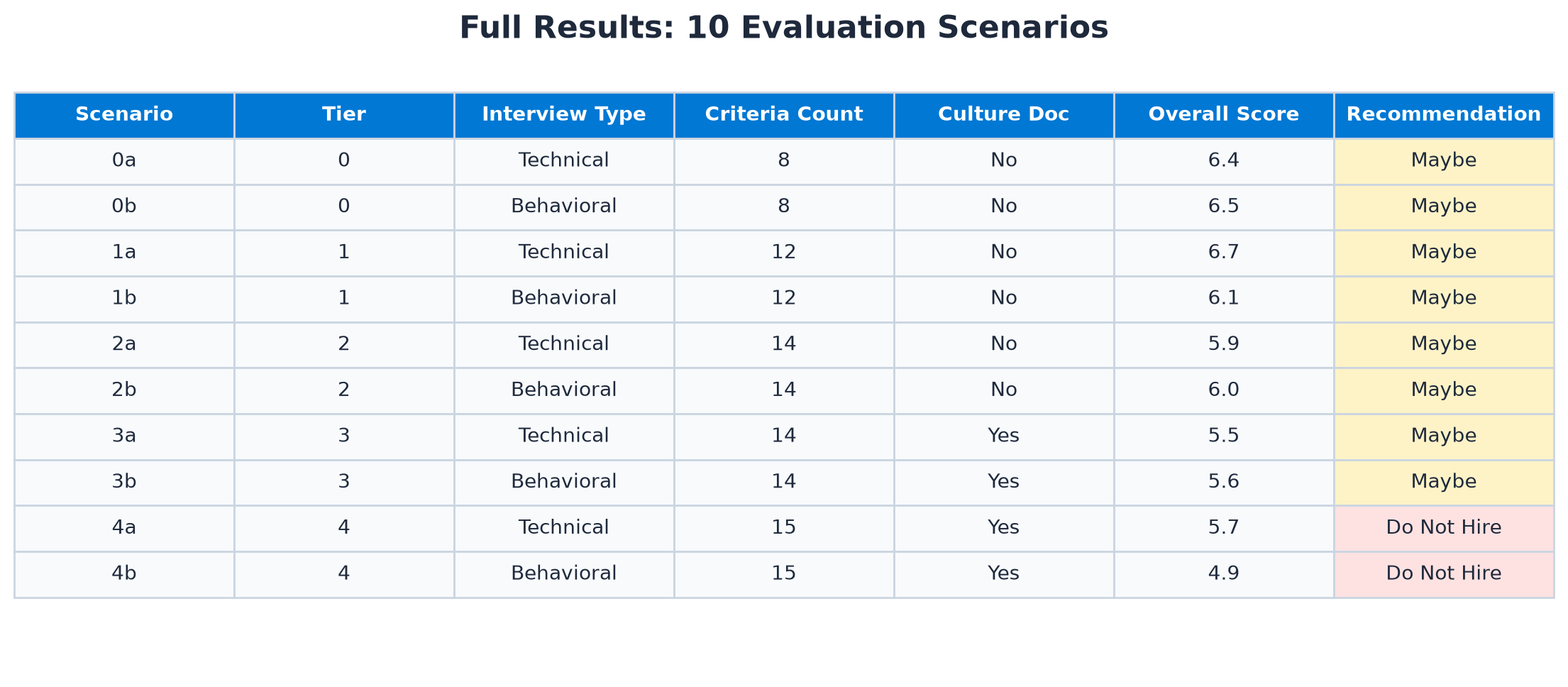
The overall score dropped from 6.5 to 4.9. The recommendation flipped from "maybe" to "do not hire." Same candidate. Same transcript. Same AI model. The only variable was the configuration.
What the Data Shows
1. The AI scores what you tell it to score
The difference between Tier 0 (6.5, "maybe") and Tier 4 (4.9, "do not hire") is 1.6 points and a recommendation flip. The candidate's arrogance was always in the transcript. But until we added criteria that measured interpersonal behaviour, the AI had no basis to penalize it. An evaluation tool measures what you point it at. A thermometer does not measure blood pressure.
2. Weights control the outcome
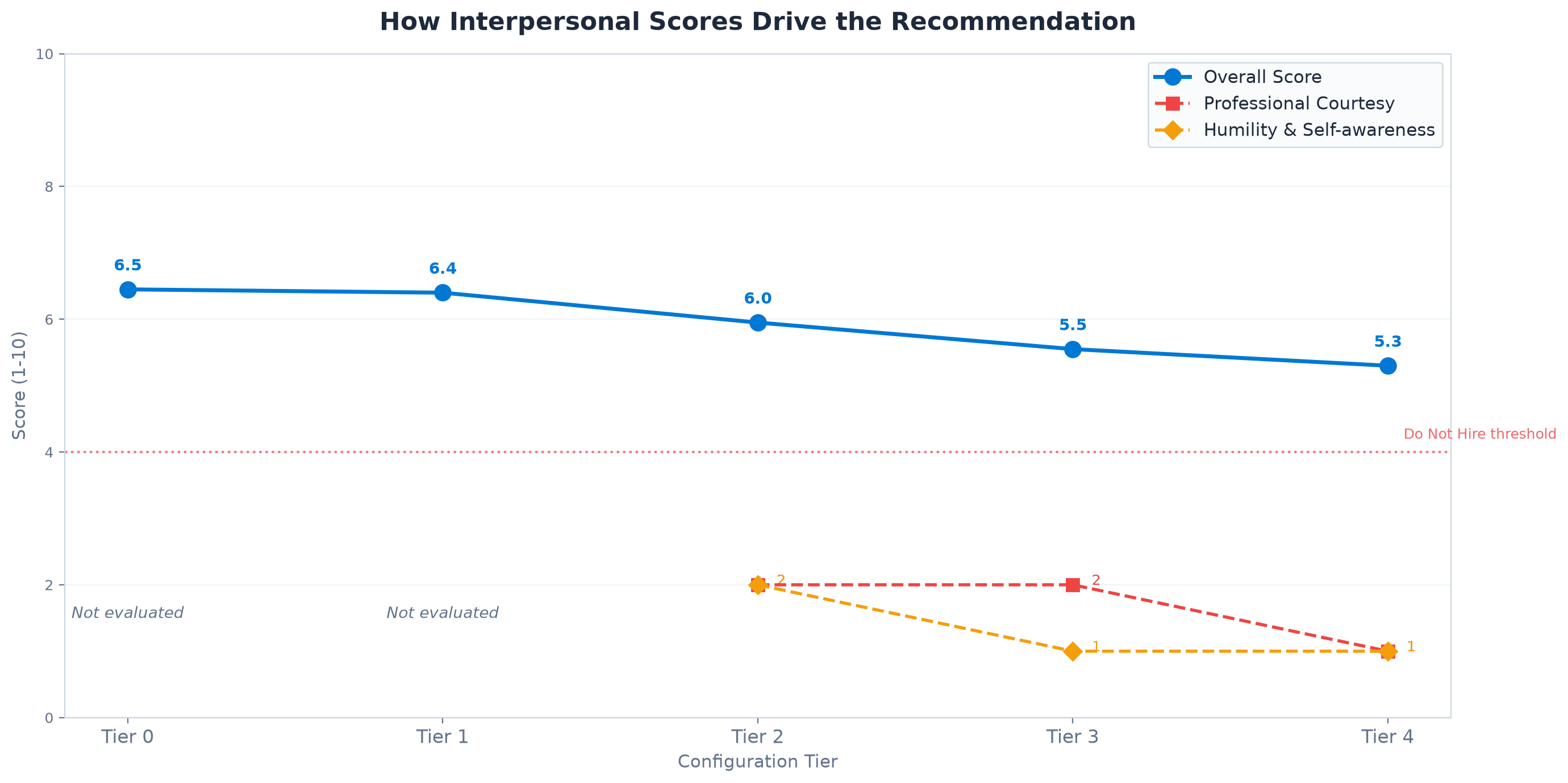
Professional Courtesy scored 2/10 in Tier 2 (weight 4). The same criterion scored 1/10 in Tier 3 when the culture document provided concrete evidence of cultural mismatch. At weight 5 in Tier 4, these low scores pulled the overall average down enough to flip the recommendation.
A criterion at weight 5 has five times the influence of a criterion at weight 1 on the final score. If you care about something, give it weight.
3. Culture documents provide decisive context
The drop from Tier 2 to Tier 3 is entirely caused by the culture document. The criteria were identical. Humility went from 2/10 to 1/10. The AI could now match the candidate's "the biggest obstacles are usually the other support staff" against a company that explicitly values collaborative spirit and respect. Without the culture document, that statement is merely unprofessional. With it, it is a direct cultural mismatch.
4. The AI exercises judgment, not just math
The most interesting result is Tier 4a: overall score 5.7, recommendation "do not hire." A pure scoring system would label 5.7 as "maybe." But the AI overrode the numerical average because it identified what it called "serious credibility concerns," a pattern of dismissiveness and self-aggrandizement that it judged incompatible with the role. This is by design. The evaluation prompt allows "do not hire" when there are serious concerns, regardless of the score.
A candidate who scores 8 on Calendar Management but 1 on Humility is not a "4.5 average." They are a risk.
What About Voice Tone and Privacy?
The third question was about privacy. The AI does not analyze voice tone, pitch, or accent. Under the EU AI Act and GDPR, we consider voice biometric analysis too risky for hiring decisions. No voice-based personality scoring, no accent detection, no emotion recognition from audio.
But the AI absolutely evaluates the content of what the candidate says. Boastful claims, dismissive language about colleagues, evasive answers, lack of concrete evidence: all of these are assessed from the transcript text. The candidate in our experiment was flagged not because of how he sounded, but because of words like "most PAs do not even know these certifications exist." That is a text signal, not an audio signal.
The key is giving the AI criteria that make these signals relevant to the evaluation. Without a criterion for Professional Courtesy, dismissive language is just a data point with nowhere to land.
Practical Checklist
Five minutes of setup that changes everything:
-
Start with AI-generated criteria, then edit. Accept the suggestions, but review them. Remove criteria that do not matter for your role. Add the soft skills and behavioural expectations that live in your head but not in the job description.
-
Upload your files. Job description as a PDF. Competency framework. Culture document. The AI uses all of them. You do not need to copy-paste text into the details field.
-
Set appropriate weights. If the role is client-facing, set Communication and Professional Courtesy to weight 4 or 5. If a certification is mandatory, set it high. If a skill is nice-to-have, set it to 1 or 2.
-
Choose the right interview type. For roles where interpersonal skills matter, select Behavioral or Cultural Fit, not just Technical. You can select multiple types.
-
Write down your culture expectations. Even a brief list in the recruiter notes: "We value directness, humility, and team-first thinking." That sentence alone gives the AI evaluation context it cannot get from a job description.
-
Recalibrate your score expectations. A 7 out of 10 is a strong candidate. Do not wait for a 9.
Limitations and Transparency
This experiment used one candidate persona, one job description, and one AI model (GPT-5.4). Different candidates, roles, and models may produce different sensitivity to criteria changes. The candidate was designed with an obvious interpersonal problem to create a clear test case. Real candidates are more nuanced.
Each evaluation ran independently, so natural variation between runs exists. The technical vs. behavioral interview framing produced slightly different scores (typically 0.1 to 0.8 points), confirming that interview type also affects outcomes.
We share this data openly because we believe AI evaluation tools should be transparent about what they measure and how configuration affects results. The full evaluation PDFs for all 10 scenarios are available upon request.