The Problem We Didn't Expect
We're building a product that uses AI to analyze job interviews. The recruiter records the interview, our system transcribes it, and GPT-5.4 evaluates the candidate on a scale from 1 to 10 against the job requirements.
Before launch, we needed to answer a simple question: how accurate is this?
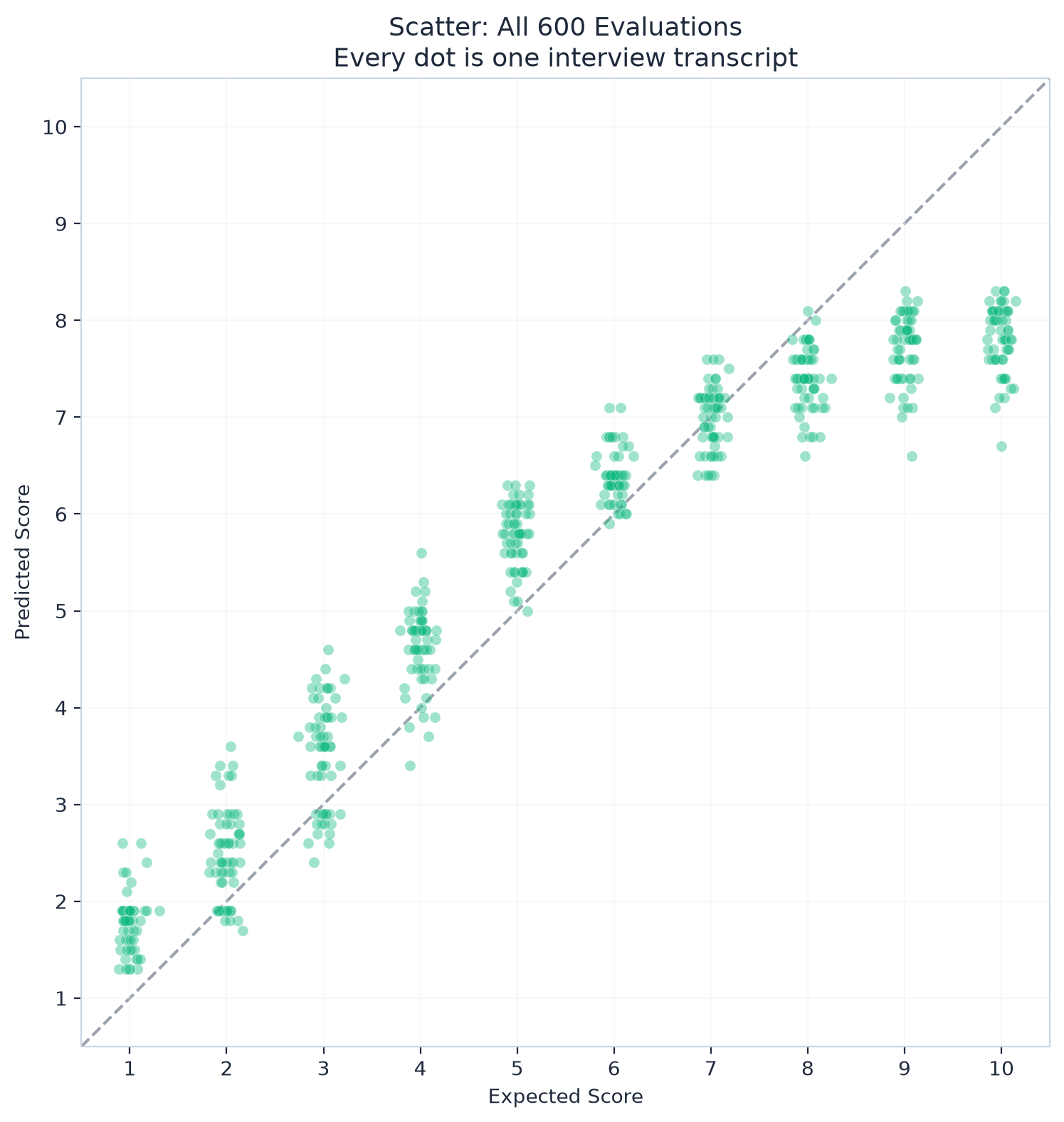
So we generated 600 synthetic interview transcripts. Each one was designed to reflect a specific quality level, from 1 (terrible candidate) to 10 (exceptional). Four different job positions, five interview types, three durations. We ran every single one through the same production prompt that real candidates would get.
The overall numbers looked promising. Mean Absolute Error of 0.82 on a 10-point scale. 94% of scores within 2 points of the expected value. Correlation of 0.96.
Then we looked closer.
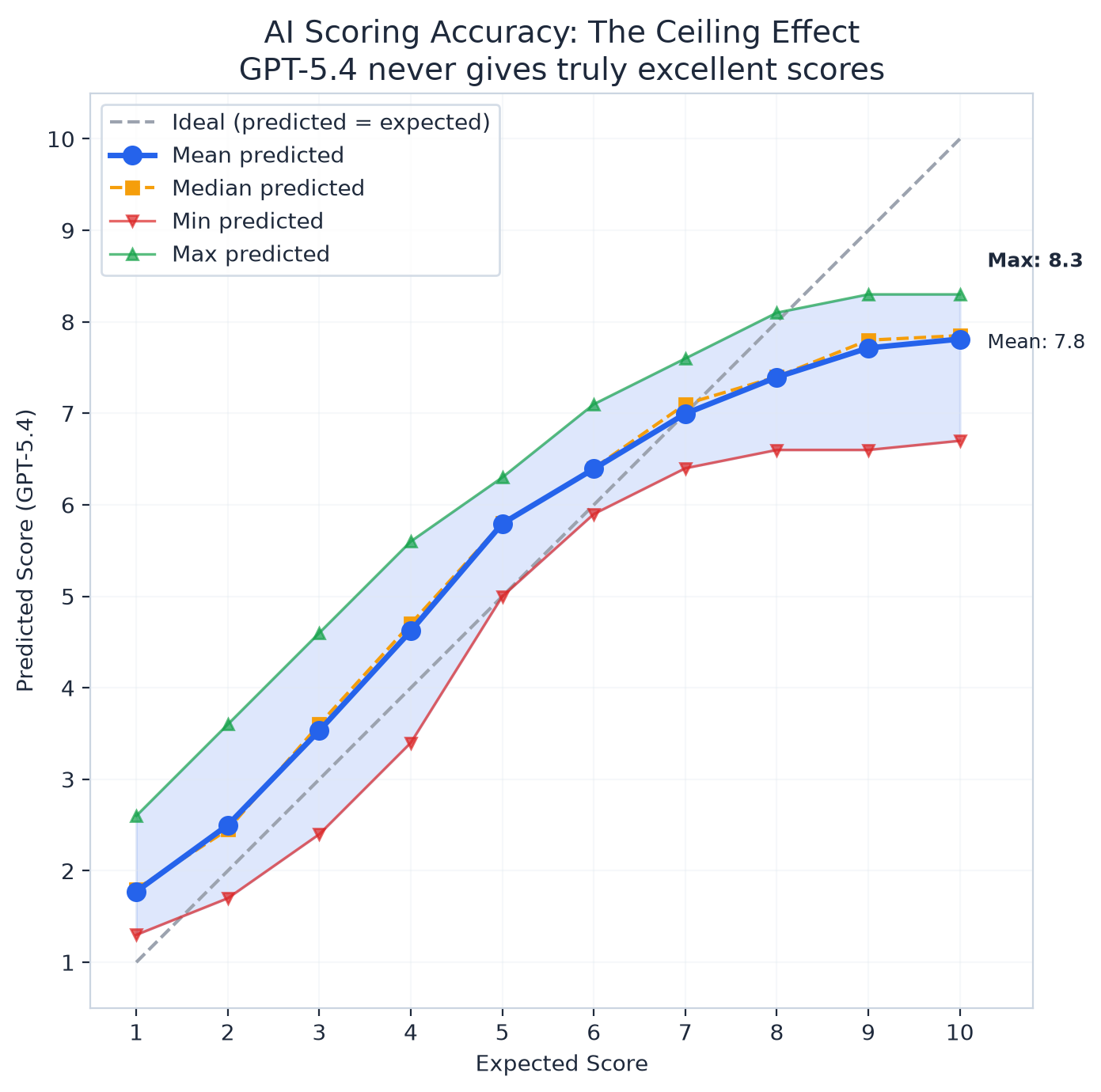
Everyone Above 8 Gets the Same Score
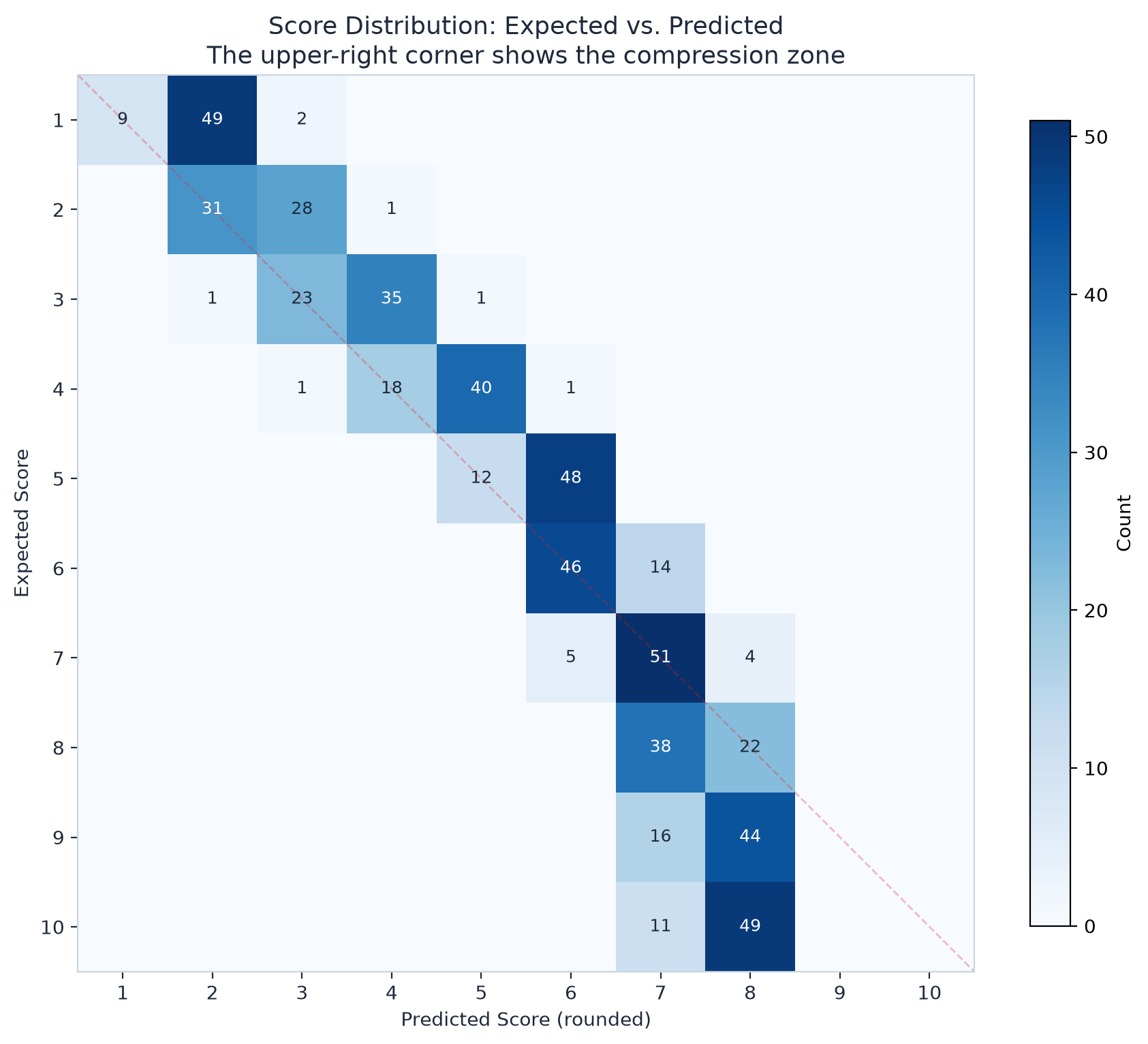
Here's what the data actually shows, broken down by expected quality level:
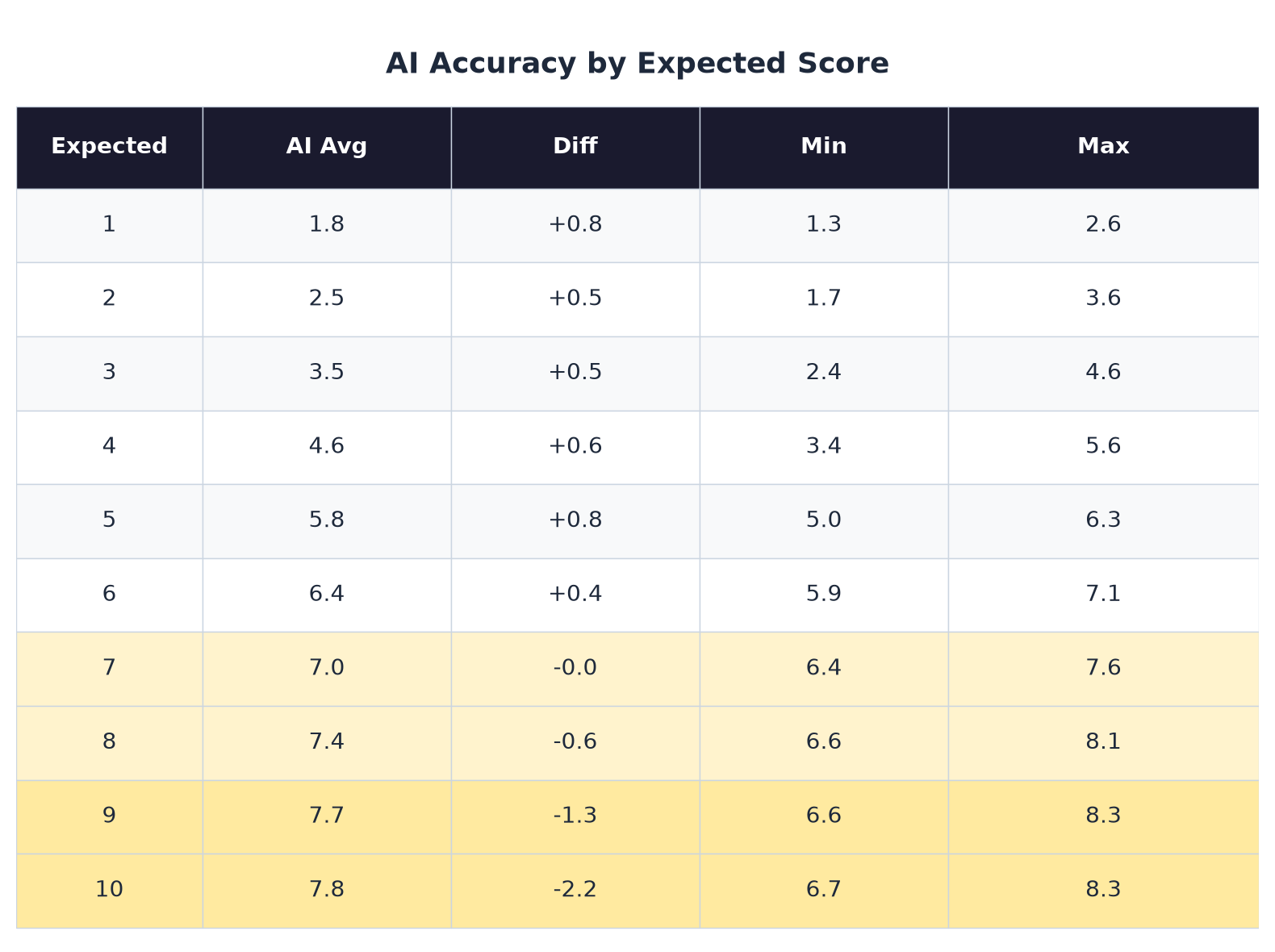
Read that last row. A candidate who deserves a perfect 10 gets a 7.8. The maximum score GPT-5.4 ever gave across all 600 evaluations was 8.3.
Scores 1 through 6? Fine. The model is generous. It gives weak candidates a little extra credit. Score 7 is perfect. Zero bias. But above that, everything collapses.
An 8, a 9, and a 10 all look like a ~7.5.
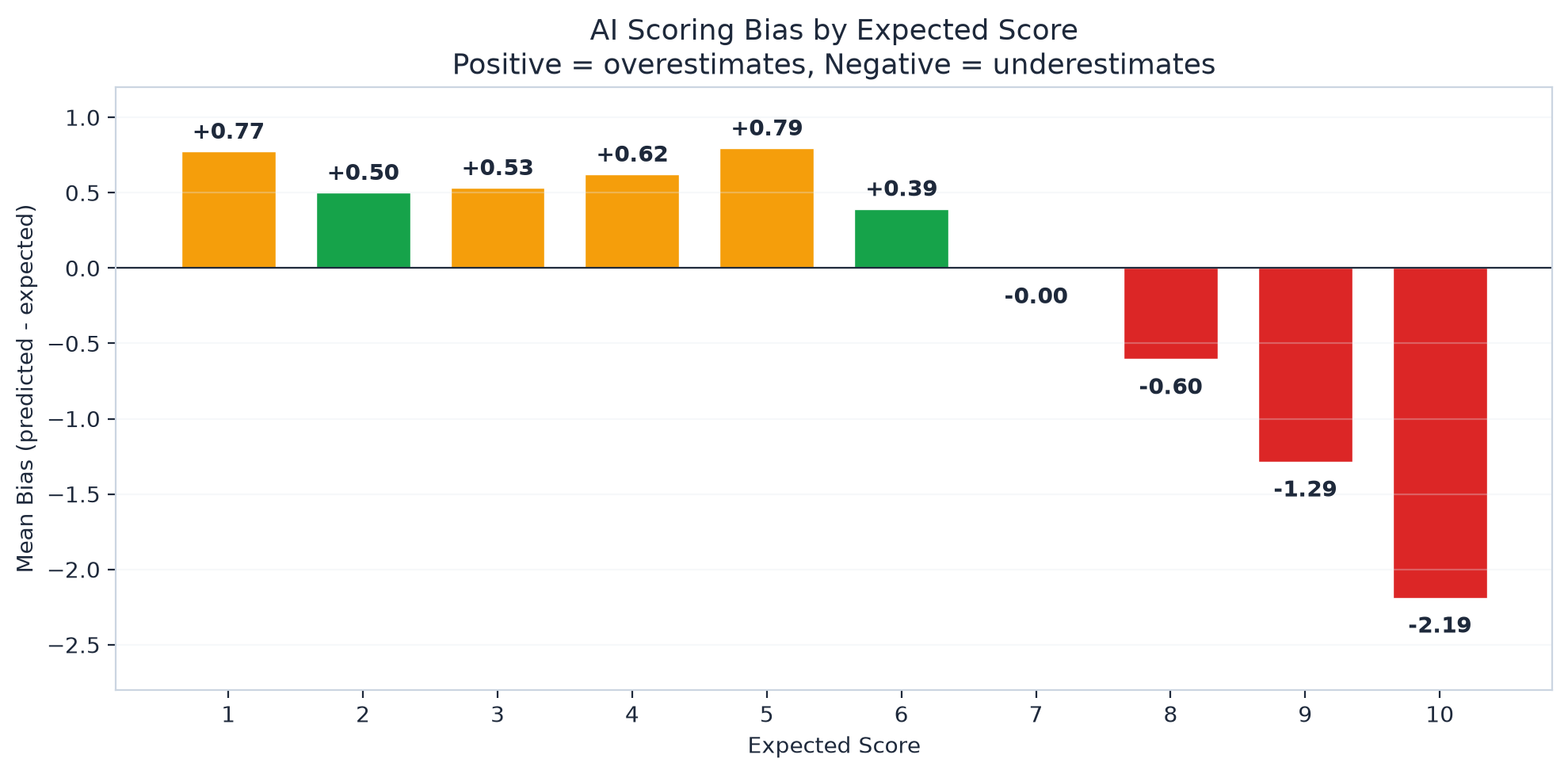
This Is Not a Bug
We didn't spend weeks trying to "fix" this, because the explanation was obvious once we looked at the data.
The problem is deeper than prompting. LLMs are trained on millions of evaluations written by humans. And humans almost never write "this is perfect, 10/10, no notes." Critical analysis is everywhere in training data. Unqualified praise is rare.
So the model learned a rule: a responsible evaluator always finds something to improve.
When it evaluates a strong candidate it'll say something like "excellent technical depth, but could have provided more specific metrics." For a top candidate: "outstanding answer, though didn't fully address the edge case." These are often valid observations! But they systematically prevent the score from ever reaching the top.
Does It Matter? Yes and No.
For filtering, the ceiling effect doesn't matter at all. The scores map cleanly to three decision tiers: 1-4 (no hire), 5-6 (maybe), and 7-10 (hire).
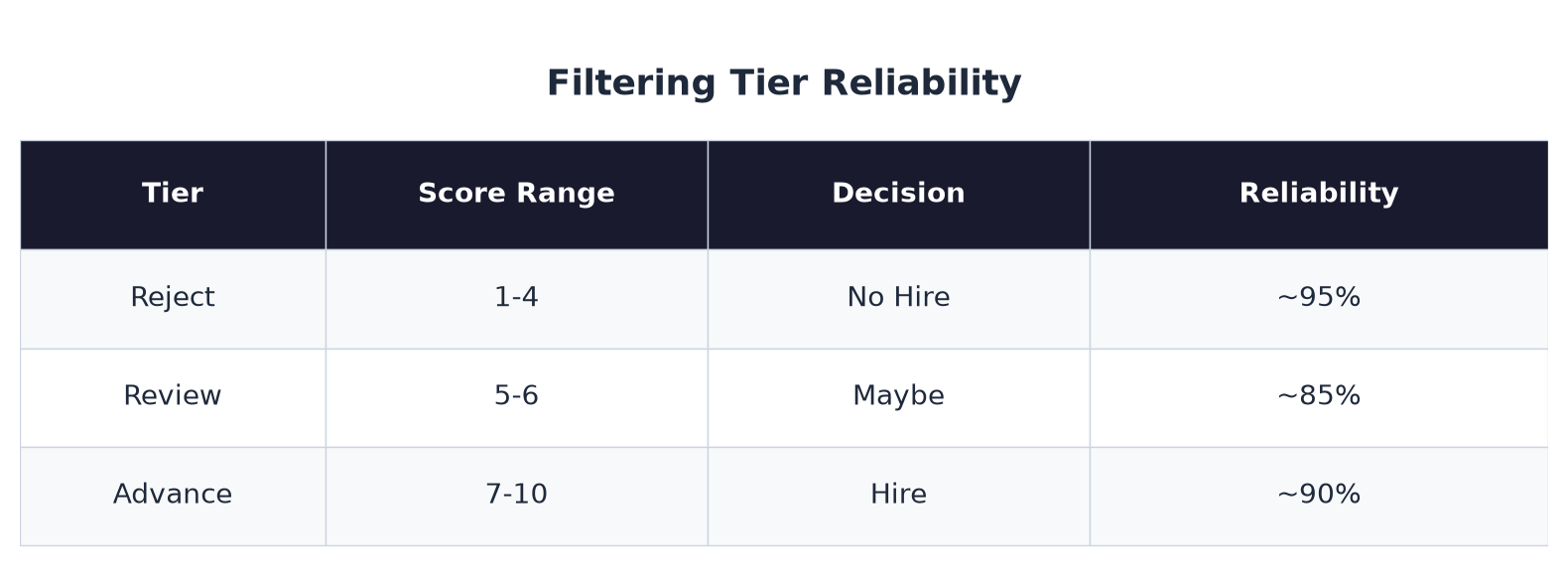
If your question is "should this person move to the next round?" AI gives you a reliable answer. Scores 1-4 reliably identify unqualified candidates (~95%). The "maybe" zone of 5-6 is solid (~85%). And 7-10 reliably identifies strong candidates.
But if your question is "who is the BEST candidate among our finalists?" the scoring system is useless. Three candidates with scores of 7.5, 7.6, and 7.8 might actually be a 10, a 9, and an 8. Or an 8, a 10, and a 9. The scores don't tell you.
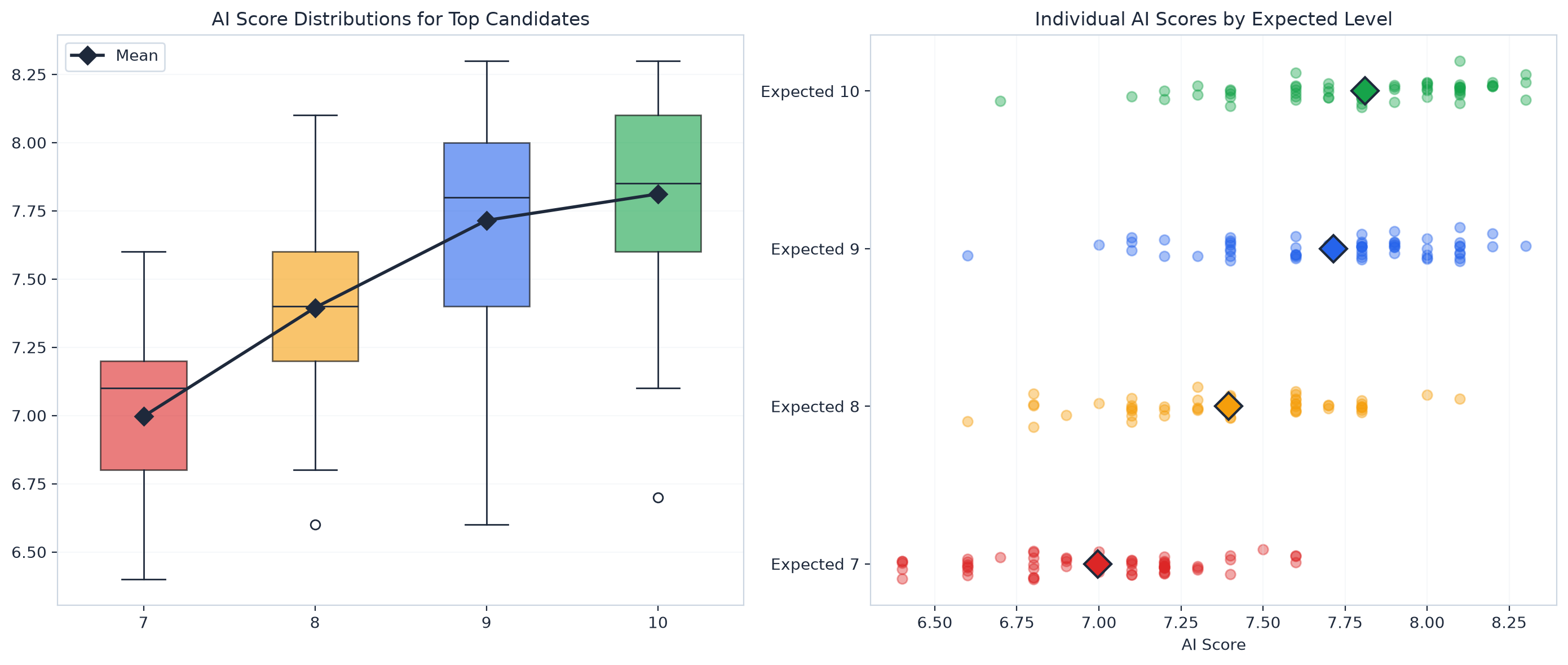
The conclusion was clear: for candidates scoring above 7, individual evaluation alone is not enough to tell you who's best.
The Plot Twist: "Don't Score Them. Rank Them."
Instead of asking GPT-5.4 "give this candidate a score from 1 to 10," we asked:
"Here are four candidates who all interviewed for the same position. Here are their individual evaluations. Rank them from best to worst, and explain your reasoning."
We built 60 of these comparison groups. Each group had 4 candidates with expected scores of 7, 8, 9, and 10. Same positions, same interview types, same durations as before. The only difference: instead of evaluating one candidate at a time, the model saw all four at once and compared them directly.
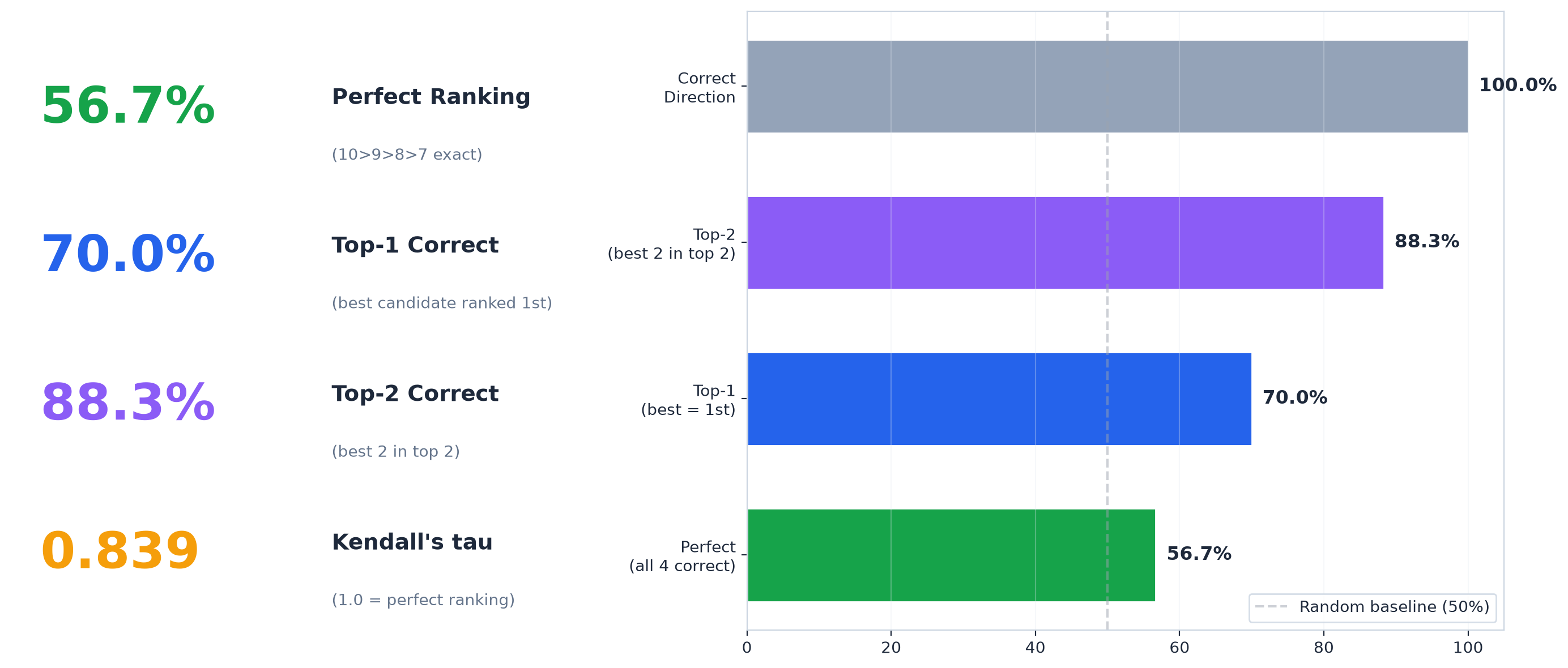
The results:
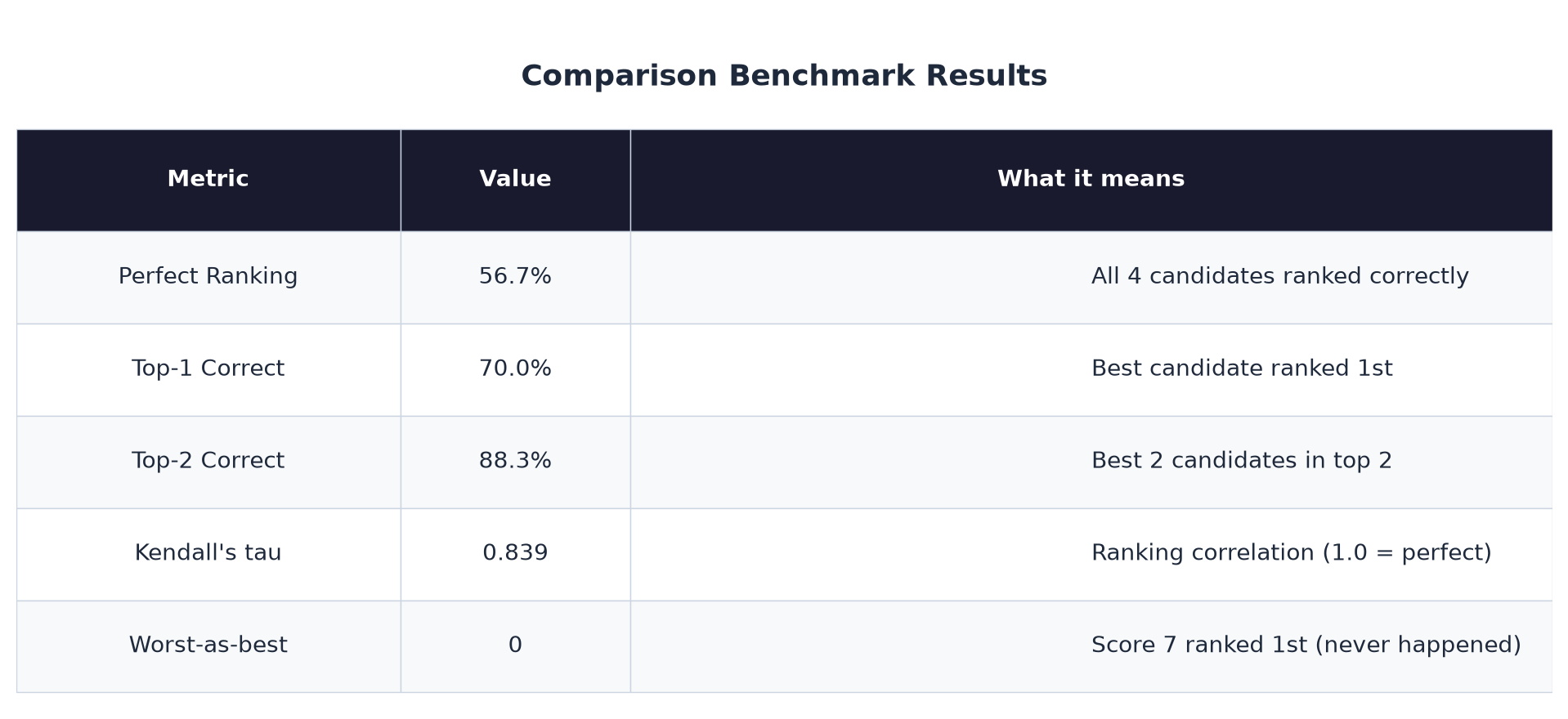
Let that sink in. The same model that can't tell an 8 from a 10 when scoring individually correctly sorts them 57% of the time and gets the top 2 right 88% of the time when comparing directly.
What Happens When It's Wrong?
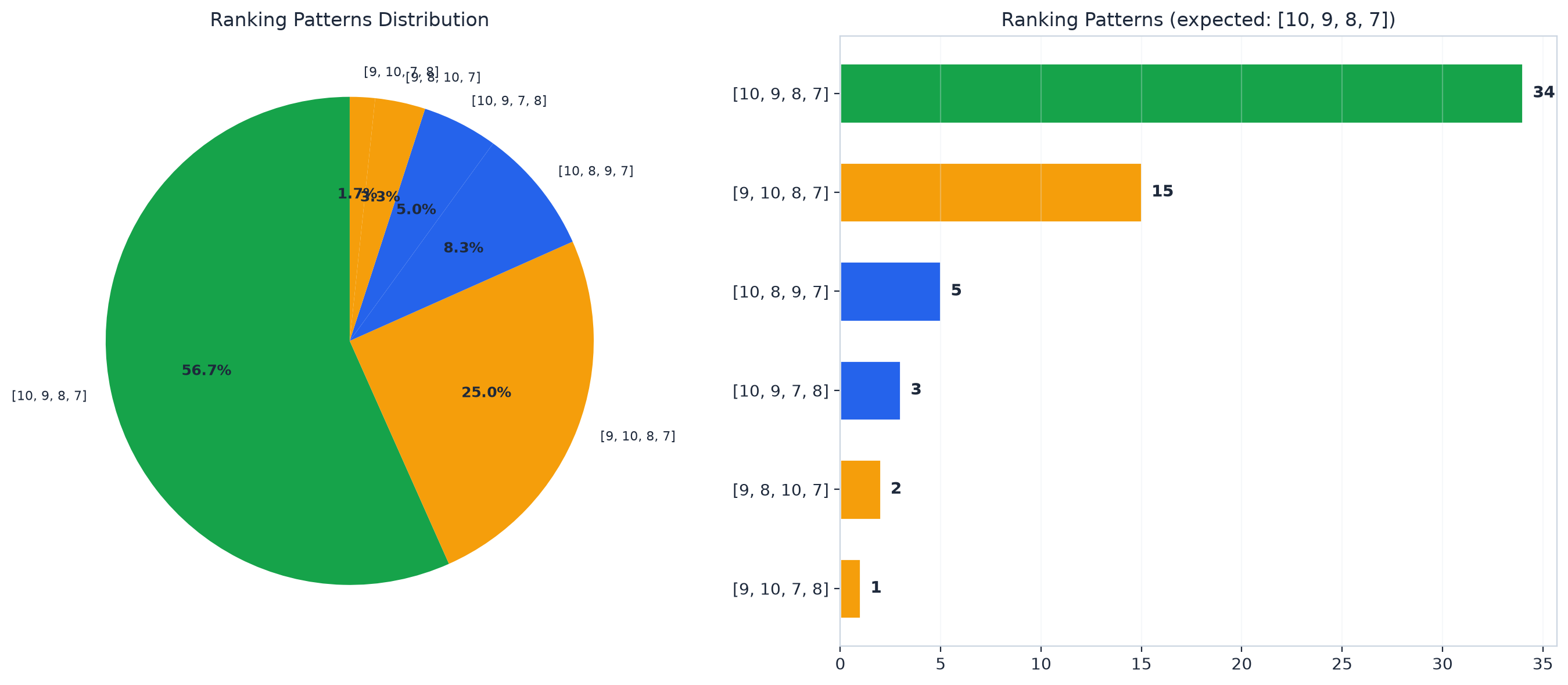
Here's every ranking pattern that appeared across 60 comparisons:
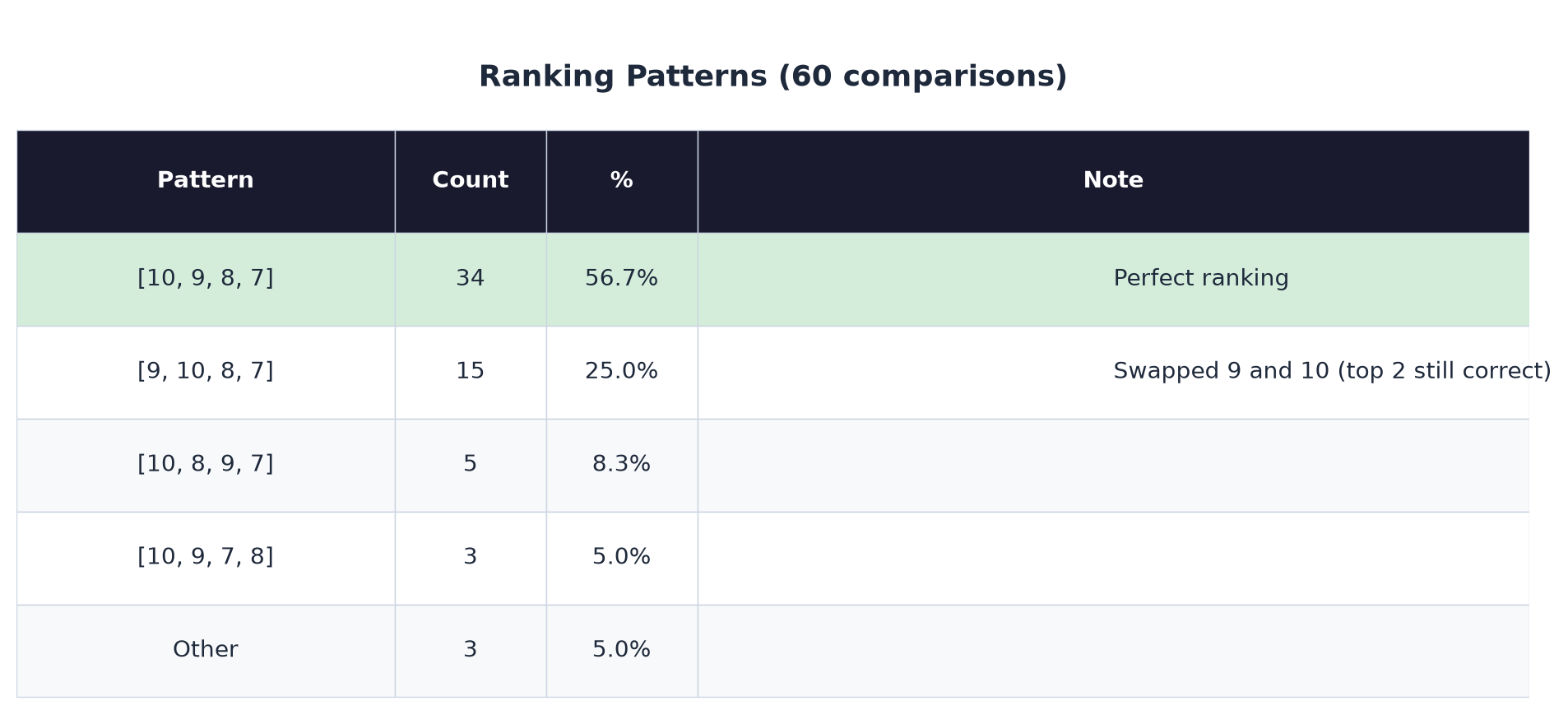
The most common error is swapping 9 and 10. That happened 15 times out of 60. And even then, both candidates are still in the top 2. A recruiter seeing this ranking would interview both of them anyway.
The weakest candidate (score 7) was ranked dead last in almost every case. The AI reliably knows who doesn't belong at the top.
![]()
Why Does Comparison Work When Scoring Doesn't?
Think about it this way.
Scoring is like asking a teacher: "Is this essay an A or a B+?" That's hard. The difference between A and B+ often comes down to gut feeling and calibration.
Comparison is like asking: "Which of these four essays is the best?" That's much easier. You can read them side by side, compare specific passages, and spot differences that would disappear in individual grading.
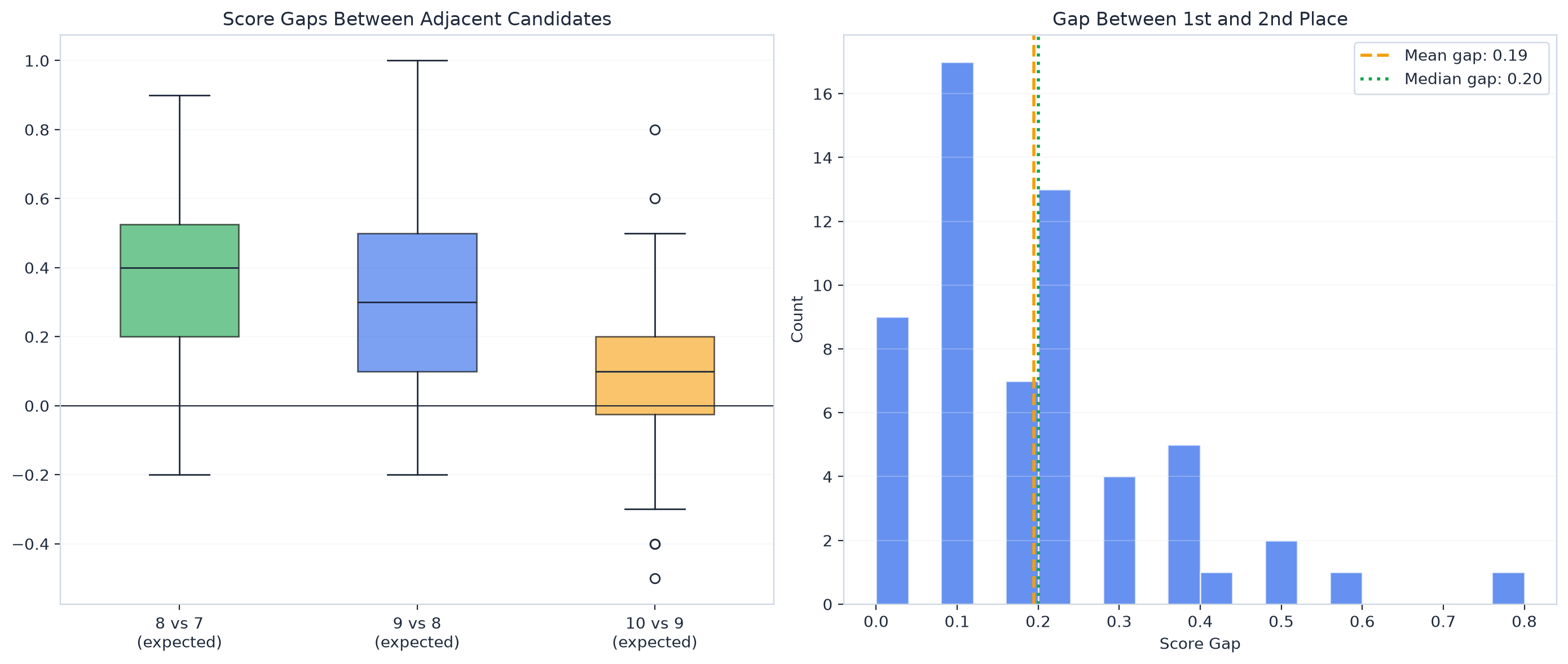
When GPT-5.4 evaluates one candidate, it reads the transcript, matches answers to requirements, and has to pick a number on an absolute scale. It's conservative. It always finds something to nitpick, so the score gets pulled down.
When it compares four candidates, the task is fundamentally different. It reads all four evaluations and makes relative judgments: "Candidate A gave a more detailed example than C," "B demonstrated deeper technical understanding than D." These relative observations are high-signal, and they don't get washed out by the "always find room for improvement" tendency.
The Two-Stage Pipeline
These findings led us to a design that turns the weakness into a strength:

Stage 1: Filter with individual scores.
Every candidate gets an individual evaluation. The AI reads their interview transcript, evaluates them against job requirements, and produces a score. This is the "gate":
- 1-4: Screen out. Don't waste anyone's time.
- 5-6: Flag for human review.
- 7-10: Advance to shortlist.
This stage is fast (one API call per candidate) and reliable. The ceiling effect doesn't matter because you're only making a binary decision (pass/fail), not ranking.
Stage 2: Rank with direct comparison.
Once candidates are evaluated, the recruiter can select which interviews and candidates to compare head-to-head. The AI reads all their individual evaluations together, produces a ranking with detailed trade-off reasoning, and highlights specific strengths and weaknesses relative to each other.
This is where the real value is. 88% of the time, the top 2 candidates in our benchmark were correctly identified. And the reasoning is specific: not just "7.8 vs 7.6" but "Candidate A demonstrated stronger system design in the infrastructure scenario, while Candidate B showed better cross-team communication."
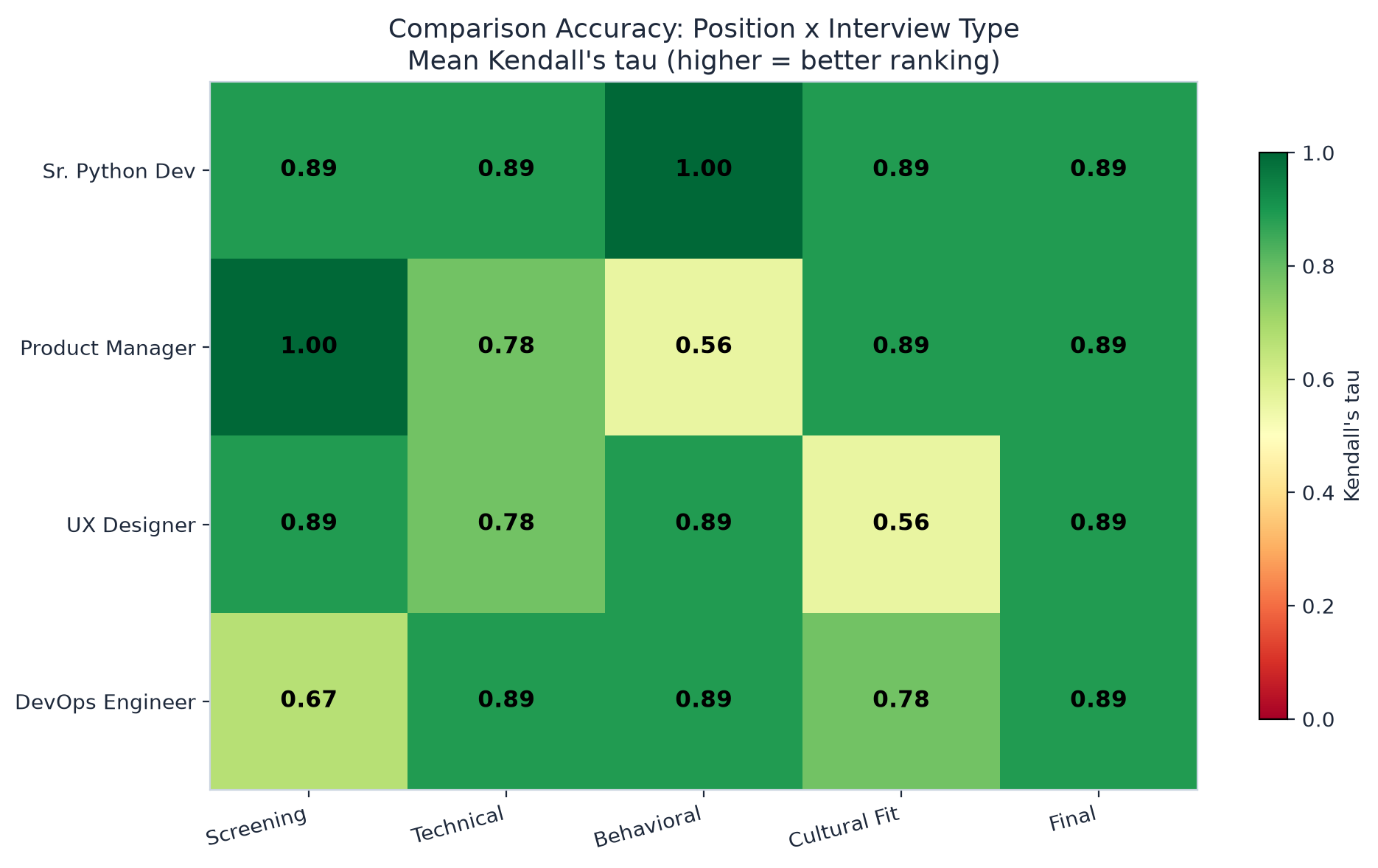
Where It Still Struggles
Not everything is perfect. Some breakdowns from the data:
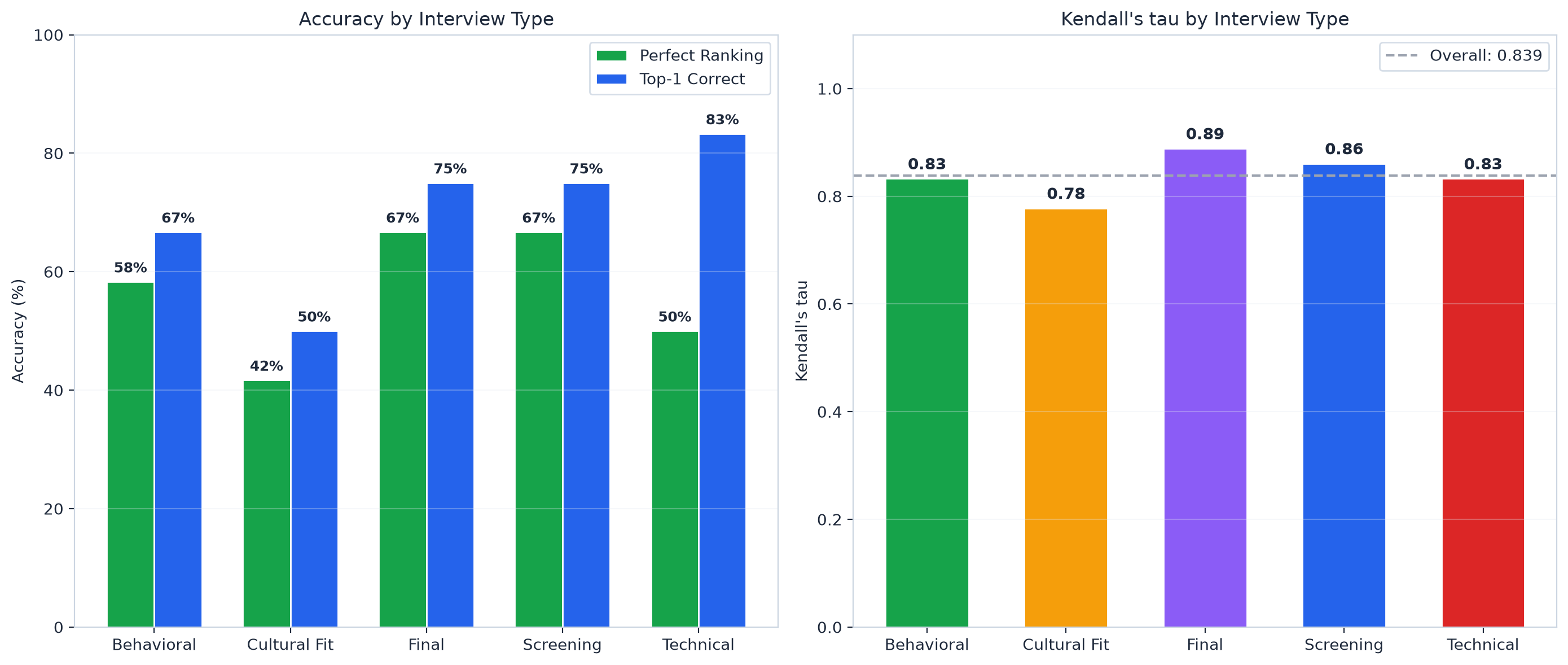
By interview type:
- Technical interviews had the highest accuracy (83% top-1 correct)
- Cultural fit had the lowest (42% perfect ranking)
This makes sense. Technical skills are easier to compare objectively. "Did they handle the edge case or not?" is a clearer signal than "would they fit in our team?"
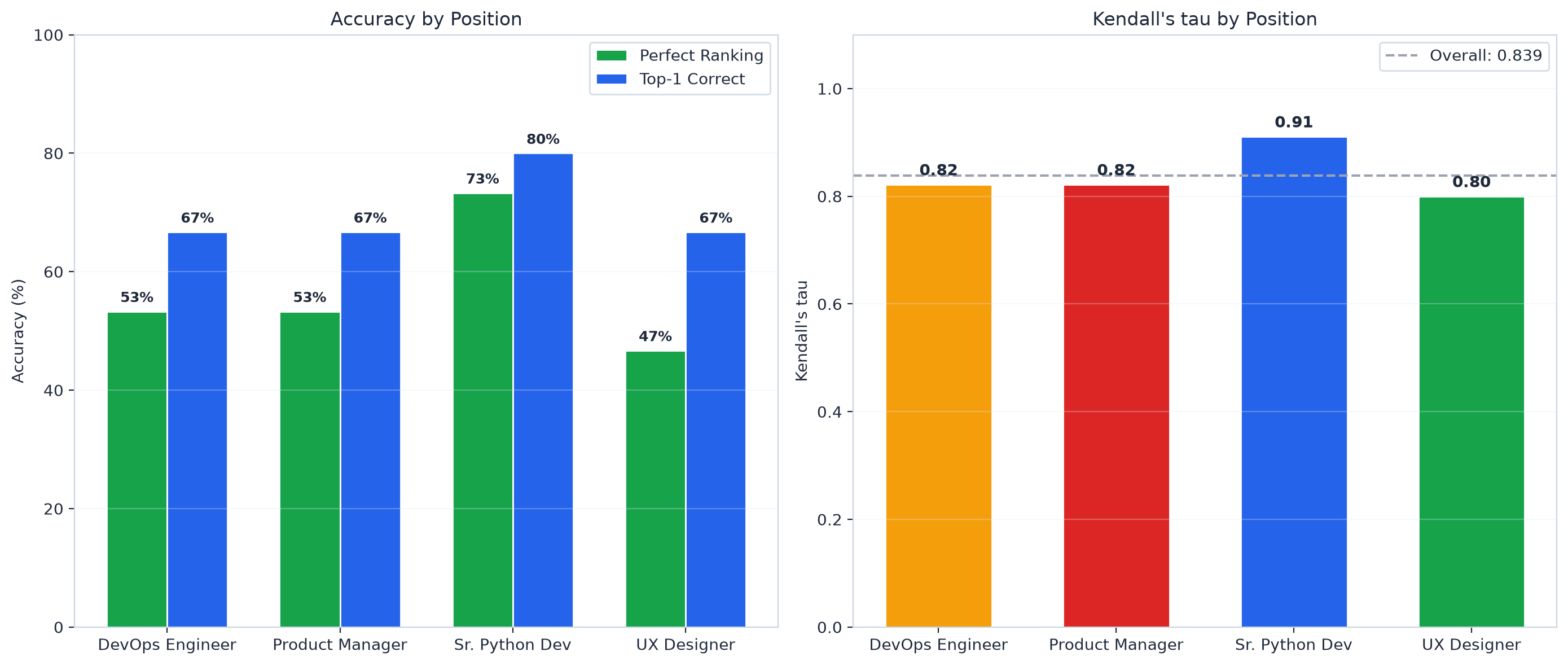
By position:
- Senior Python Developer showed the best results (73% perfect ranking)
- UX Designer was the hardest (47% perfect)
Again, more objectively measurable skills lead to better comparisons.
What This Means for Your Hiring Process
If you're evaluating AI tools for candidate assessment, here's what our data says you should expect, and demand.
-
AI can reliably screen candidates for you. The three tiers, 1-4 (no hire), 5-6 (maybe), 7-10 (hire), were correct the vast majority of the time. That means fewer hours spent reviewing candidates who clearly aren't a fit, and fewer strong candidates slipping through the cracks.
-
Don't trust small score differences between top candidates. If a tool tells you Candidate A scored 7.8 and Candidate B scored 7.6, that difference is meaningless. Both are strong. Individual scores alone cannot tell you who's better among your finalists.
-
Ask how the tool ranks finalists. Any AI interview tool that only gives you individual scores is leaving value on the table. Direct comparison, where the AI reviews multiple candidates side by side, produces dramatically better results. 88% top-2 accuracy vs. scores that are essentially random above 7.
-
Soft skills still need your judgment. AI comparison worked best for technical and situational interviews. For cultural fit and personality-based questions, the ranking accuracy dropped significantly. These still need your team's eyes and ears.
-
Look for reasoning, not just numbers. The most useful output isn't "Candidate A: 1st place." It's "Candidate A demonstrated stronger system design thinking, while Candidate B showed better stakeholder communication." That kind of trade-off analysis actually helps you make a hiring decision.
The Bottom Line
GPT-5.4 has a ceiling. It will never give your best candidate a 10. It will probably give them a 7.8 and find something to nitpick.
But ask it to compare that 7.8 against three other 7.8s, and it'll almost certainly put the right person on top.
The ceiling effect isn't a bug you fix. It's a limitation you design around, and when you do, the results are surprisingly good.
This article is based on original research by AI Interview Analyzer. The evaluation used GPT-5.4 (gpt-5.4-2026-03-05) deployed on Azure OpenAI. All 600 transcripts were synthetic, generated with controlled quality levels. 60 comparison groups used 4 candidates each from the top tier (expected scores 7-10). No real candidate data was used.