The Honest Count
The product is called AI Interview Analyzer. So how much of it is actually AI?
Ten features. Three phases. One decision at the end, and a human makes it.
Nine features run on Azure OpenAI, GPT-5.4. One runs on Azure Speech. That is the whole stack. No hidden models. No black box labelled "secret sauce." Every feature has a job you can describe in a sentence.
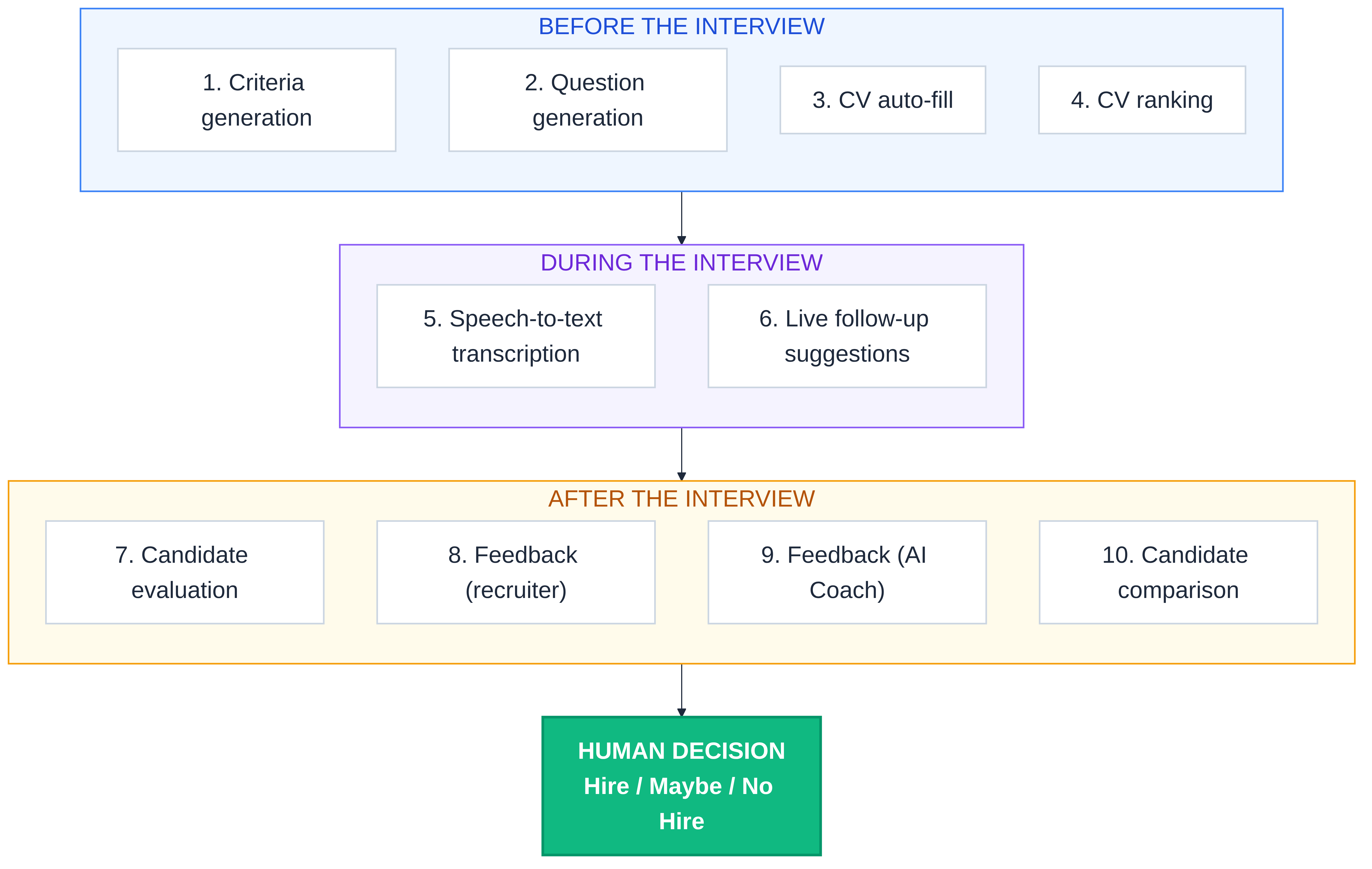
Here is what each one does.
Before the Interview
1. Evaluation Criteria
You describe the role. You pick the interview type. You upload a job description if you have one. The AI drafts 8 to 15 evaluation criteria, each with a weight from 1 to 5.
You edit them. Change weights. Delete what is wrong. Add what is missing. The AI drafts. You decide what matters.
We wrote a longer piece on why the criteria matter more than the AI that scores them: Why AI Did Not Flag the Arrogant Candidate.
2. Interview Questions
Once the criteria are set, the AI produces a reference sheet of interview questions. Twelve to sixteen of them, grouped into three buckets: technical, behavioral, situational. Every question maps to at least one criterion.
Read them. Take the ones that help. Ignore the rest. The sheet is a warm-up, not a script.
3. CV Auto-Fill
You upload a CV. The AI reads it and fills four fields: name, email, phone, preferred language. It takes a few seconds.
That is the whole feature. A small robot typing for you.
4. CV Ranking
You can rank every CV in a recruitment against the criteria. The AI scores each one, writes a short justification, and gives you an ordered list. Exportable as PDF.
A warning. Candidates also have AI. A CV written with help from GPT-5 will look, on paper, better than a real CV from a better candidate who cannot prompt well. Treat the ranking as a reading order, not a rejection list. Read the top. Sample the middle. Do not cut someone because their honest resume lost to a generated one.
During the Interview
5. Live Transcription
Azure Speech transcribes the conversation as it happens. Twenty-four official EU languages. The transcript shows up on screen while you talk and stays with the interview record when you stop.
6. Live Follow-Up Suggestions
While you interview, a side panel quietly updates. Every sixty seconds the AI looks at the full transcript so far, compares it to your criteria, and suggests five questions you could ask next.
The candidate mentions a project. The AI suggests: What was your specific contribution? The answer is vague. The AI suggests: Can you give a concrete example?
It does not interrupt. It does not speak. It does not decide. It whispers. You choose whether to listen.
After the Interview
When the recording ends, processing starts on its own.
7. Candidate Evaluation
This is the heart of the product.
The AI scores the candidate against each criterion, one to ten. For anything it scores, it cites the exact quote that earned the score. If a topic never came up in the conversation, the AI flags the criterion as not assessed with a neutral placeholder of 5 and a note that it was not verified in this interview, instead of guessing a real score. A final recommendation at the end: Hire, Maybe, or No Hire.
What it will not do matters as much as what it will. It will not score something the candidate never said. It will not guess personality from voice. It will not compare this candidate to other candidates. It matches answers to criteria and shows its work.
8. Feedback for the Candidate
The AI drafts a message to the candidate, in the candidate's language. Specific. Professional. Fully editable.
You read it. You adjust the tone. You sign it with your name. It goes out as a message from you, because it is one.
9. Feedback from the AI Coach
A second draft, different voice. This one is labelled as coming from the AI Coach, not from you. It gives the candidate development advice based on the interview: topics to study, skills to sharpen, patterns to watch.
Two drafts, two senders, two roles. A human message signed by a human. An AI message labelled as AI. Candidates know exactly which is which. That is a compliance choice, and also the right one.
10. Candidate Comparison
This is the feature that actually works.
Ask GPT-5.4 to score a single interview from one to ten, and a Nobel laureate gets an 8. A strong senior engineer also gets an 8. The model is generous in the middle of the scale and terrified of the ceiling. Every candidate ends up looking above average and nothing looks great. We wrote about it in detail: GPT-5.4 Scored 600 Interviews from 1 to 10. It Never Gave Above 8.3.
Comparison fixes that.
Instead of asking the AI "how good is this candidate, absolutely," you ask "given these three evaluations, which one shows the most specific evidence of what the role needs." Relative questions get sharper answers than absolute ones.
The AI reads every evaluation in the recruitment, ignores criteria that were not assessed in each interview (no inflation from defaults), and compares on evidence quality, not numeric scores. Two candidates with 7.5 overall can look completely different once you unpack their evidence. The output is a ranking, a criterion-by-criterion matrix, a list of trade-offs between the top contenders, a recommendation, and suggested next steps for verifying the shortlist. Exportable as PDF.
The comparison is a reading, not a draft. You read it, you disagree, you hire whoever you think is right. The AI laid out the evidence. You make the call.
What the AI Does Not Do
Every article about an AI product lists what it does. Almost none list what it refuses to do. Here is the list.
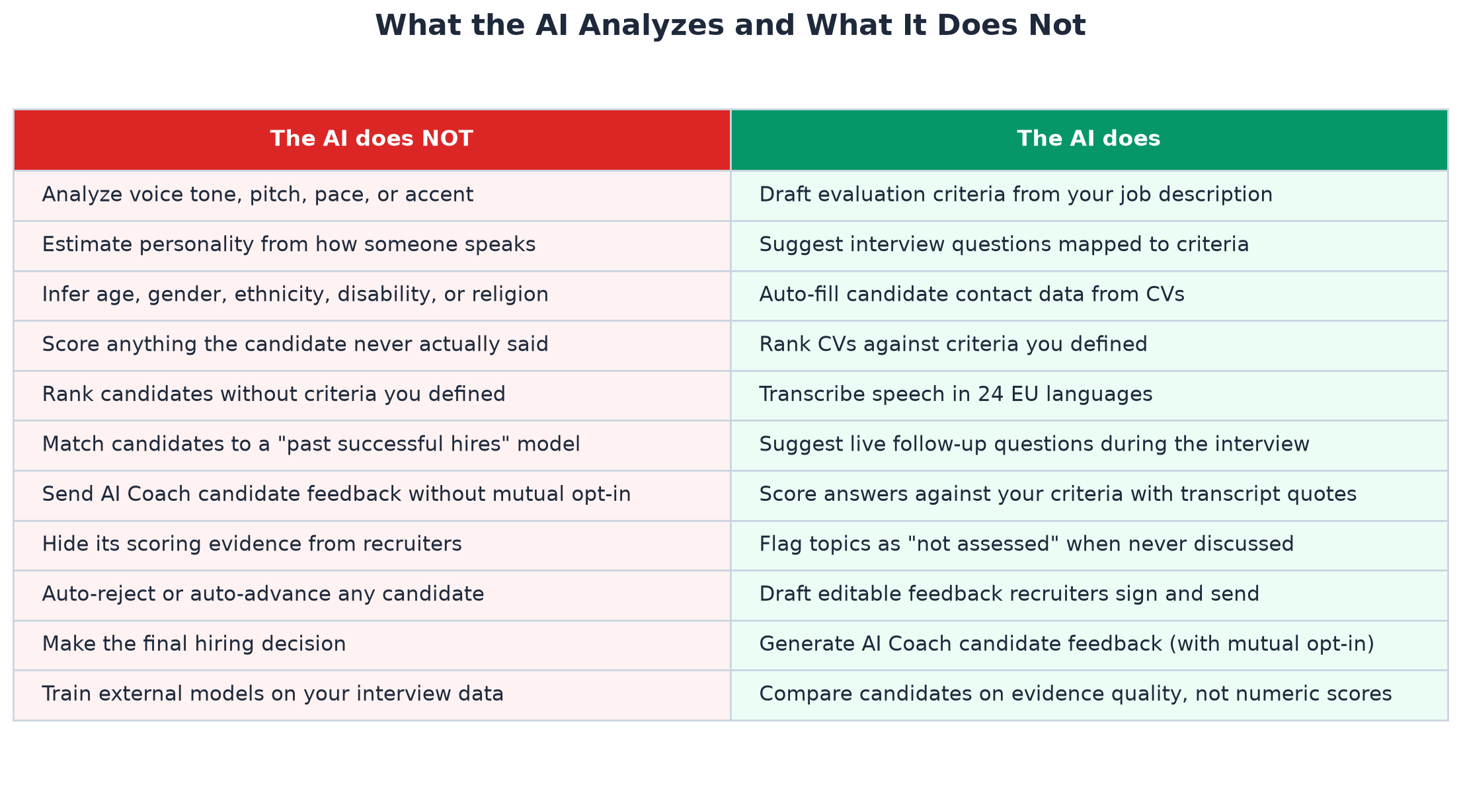
The AI does not analyze voice tone, pitch, pace, or accent. It does not estimate personality from how someone speaks. It does not infer age, gender, ethnicity, disability, religion, or sexual orientation. It does not compare candidates against a model of "past successful hires." Every score is tied to a criterion you defined and a quote from the transcript. If a topic never came up, the criterion is flagged as not assessed with a neutral placeholder score, not an invented one.
Three reasons.
Bias. Voice tone, accent, and personality scores correlate with protected characteristics. Scoring them creates legal risk we will not take on your behalf.
The EU AI Act. Interview analysis is a high-risk system under the Act. High-risk systems must be transparent, documented, and free of protected-characteristic inference. We built the product that way from day one.
Defensibility. Every real score cites a quote. Topics the candidate never discussed are flagged as not assessed with a neutral placeholder, not invented. That is what makes the output defensible if a candidate disputes the decision. Without evidence, a score is just an opinion.
Who Decides
Ten AI features. One human decision.
The AI drafts criteria. You edit them. The AI suggests questions. You choose which to ask. The AI ranks CVs. You pick who to invite. The AI transcribes. You ran the conversation. The AI whispers follow-ups. You decide whether to ask. The AI scores the candidate. You read the evidence. The AI writes feedback. You edit and sign it. The AI compares candidates. You make the hire.
That is the whole design. AI takes the work off your plate. It does not take the authority off it.
What's Next
More AI ships in 2026. From our public roadmap:
- Candidate portal with AI-generated CV (Q3): candidates apply through a portal and get an AI-tailored CV for the specific job offer, so the application itself carries more signal.
- Built-in video interviews (Q3): run interviews in the browser, no external meeting tool needed. All ten AI features above plug in the same way.
- Live coding with AI analysis (Q4): technical interviews with a code editor in the browser. The AI evaluates code, approach, and communication, and adds an automated code review to the scoring.
We will write a dedicated piece for each one when it ships.